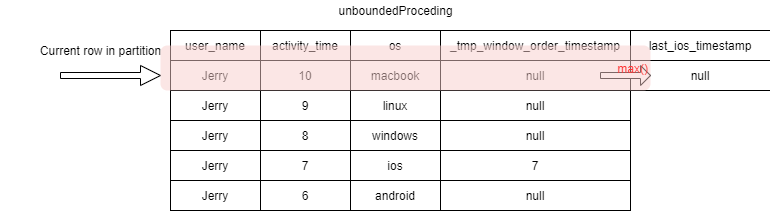
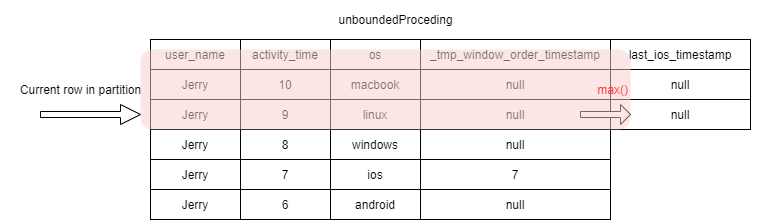
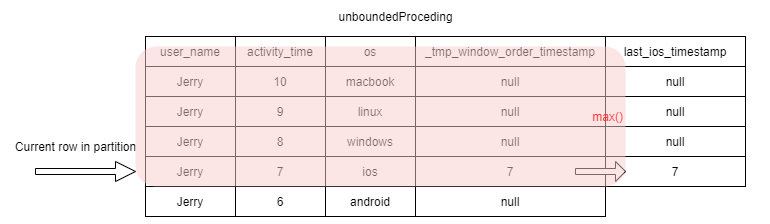
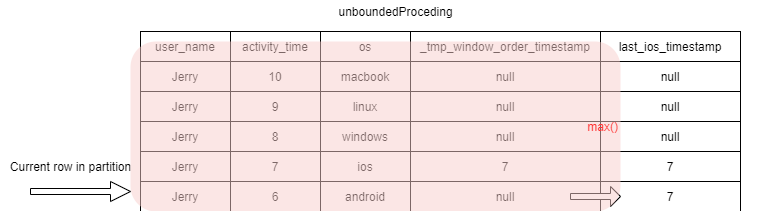
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
| 29-03-2024 09:51:54 INFO - 2024-03-29 09:51:54 JST INFO com.xxxxx.xxxxxx.xxx.xxx.executor.ExportExecutor: inputDfPath:hdfs://xxx/user/xxxx/xxx-xxx/xxx_xxx_xxx/data/dt=xxx
29-03-2024 09:51:54 INFO - 2024-03-29 09:51:54 JST INFO com.xxxxx.xxxxxx.xxx.xxx.reader.ReaderImpl: Reading data from HDFS path: [hdfs://xxx/user/xxxx/xxx-xxx/xxx_xxx_xxx/data/dt=xxx] schema: StructType(StructField(xxxxx))
29-03-2024 09:52:34 INFO - 2024-03-29 09:52:34 JST INFO com.xxxxx.xxxxxx.xxx.xxx.writer.WriterImpl: Writing data to HDFS format: [csv] mode:[overwrite] separator:[ ] compression:[gzip] path:[hdfs://xxx/user/xxxx/xxx-xxx/xxx_xxx_xxx/data/output/] header:[false] encoding:[UTF-8]
29-03-2024 09:52:34 INFO - 2024-03-29 09:52:34 JST WARN org.apache.spark.util.Utils: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.debug.maxToStringFields' in SparkEnv.conf.
29-03-2024 09:52:34 INFO - 2024-03-29 09:52:34 JST INFO com.hadoop.compression.lzo.GPLNativeCodeLoader: Loaded native gpl library
29-03-2024 09:52:34 INFO - 2024-03-29 09:52:34 JST INFO com.hadoop.compression.lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev bb4f4d562ec4888b1c6b0dec1ed7bc4b60229496]
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST ERROR org.apache.spark.scheduler.TaskSetManager: Total size of serialized results of 219 tasks (1029.1 MB) is bigger than spark.driver.maxResultSize (1024.0 MB)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST ERROR org.apache.spark.sql.execution.datasources.FileFormatWriter: Aborting job null.
29-03-2024 09:53:10 INFO - org.apache.spark.SparkException: Job aborted due to stage failure: Total size of serialized results of 219 tasks (1029.1 MB) is bigger than spark.driver.maxResultSize (1024.0 MB)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1651)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1639)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1638)
29-03-2024 09:53:10 INFO - at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
29-03-2024 09:53:10 INFO - at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1638)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
29-03-2024 09:53:10 INFO - at scala.Option.foreach(Option.scala:257)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:831)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1872)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1821)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1810)
29-03-2024 09:53:10 INFO - at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:642)
29-03-2024 09:53:10 INFO - at org.apache.spark.SparkContext.runJob(SparkContext.scala:2039)
29-03-2024 09:53:10 INFO - at org.apache.spark.SparkContext.runJob(SparkContext.scala:2060)
29-03-2024 09:53:10 INFO - at org.apache.spark.SparkContext.runJob(SparkContext.scala:2079)
29-03-2024 09:53:10 INFO - at org.apache.spark.SparkContext.runJob(SparkContext.scala:2104)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:945)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDD.withScope(RDD.scala:363)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDD.collect(RDD.scala:944)
29-03-2024 09:53:10 INFO - at org.apache.spark.RangePartitioner$.sketch(Partitioner.scala:309)
29-03-2024 09:53:10 INFO - at org.apache.spark.RangePartitioner.<init>(Partitioner.scala:171)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec$.prepareShuffleDependency(ShuffleExchangeExec.scala:224)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.prepareShuffleDependency(ShuffleExchangeExec.scala:91)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec$$anonfun$doExecute$1.apply(ShuffleExchangeExec.scala:128)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec$$anonfun$doExecute$1.apply(ShuffleExchangeExec.scala:119)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.doExecute(ShuffleExchangeExec.scala:119)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.InputAdapter.inputRDDs(WholeStageCodegenExec.scala:371)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SortExec.inputRDDs(SortExec.scala:121)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:605)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:180)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:154)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:104)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:122)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:656)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:656)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:77)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:656)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:273)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:267)
.....
29-03-2024 09:53:10 INFO - at com.xxxxx.xxxxxx.xxx.xxx.Boot$.runJob(Boot.scala:55)
29-03-2024 09:53:10 INFO - at com.xxxxx.xxxxxx.xxx.xxx.Boot$.main(Boot.scala:30)
29-03-2024 09:53:10 INFO - at com.xxxxx.xxxxxx.xxx.xxx.Boot.main(Boot.scala)
29-03-2024 09:53:10 INFO - at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
29-03-2024 09:53:10 INFO - at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
29-03-2024 09:53:10 INFO - at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
29-03-2024 09:53:10 INFO - at java.lang.reflect.Method.invoke(Method.java:498)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:904)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:198)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:228)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:137)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 230.0 in stage 0.0 (TID 261, xxx.xxx.hadoop.server, executor 13): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 364.0 in stage 0.0 (TID 281, xxx.xxx.hadoop.server, executor 13): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 476.0 in stage 0.0 (TID 209, xxx.xxx.hadoop.server, executor 14): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 238.0 in stage 0.0 (TID 259, xxx.xxx.hadoop.server, executor 71): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 464.0 in stage 0.0 (TID 274, xxx.xxx.hadoop.server, executor 8): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 394.0 in stage 0.0 (TID 233, xxx.xxx.hadoop.server, executor 15): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 392.0 in stage 0.0 (TID 212, xxx.xxx.hadoop.server, executor 8): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 513.0 in stage 0.0 (TID 247, xxx.xxx.hadoop.server, executor 33): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 479.0 in stage 0.0 (TID 254, xxx.xxx.hadoop.server, executor 94): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 365.0 in stage 0.0 (TID 211, xxx.xxx.hadoop.server, executor 16): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 458.0 in stage 0.0 (TID 286, xxx.xxx.hadoop.server, executor 16): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 300.0 in stage 0.0 (TID 283, xxx.xxx.hadoop.server, executor 42): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 308.0 in stage 0.0 (TID 279, xxx.xxx.hadoop.server, executor 75): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 134.0 in stage 0.0 (TID 231, xxx.xxx.hadoop.server, executor 75): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 440.0 in stage 0.0 (TID 278, xxx.xxx.hadoop.server, executor 89): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 374.0 in stage 0.0 (TID 277, xxx.xxx.hadoop.server, executor 85): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 343.0 in stage 0.0 (TID 237, xxx.xxx.hadoop.server, executor 85): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 345.0 in stage 0.0 (TID 265, xxx.xxx.hadoop.server, executor 3): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 441.0 in stage 0.0 (TID 267, xxx.xxx.hadoop.server, executor 100): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 502.0 in stage 0.0 (TID 214, xxx.xxx.hadoop.server, executor 79): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 465.0 in stage 0.0 (TID 227, xxx.xxx.hadoop.server, executor 54): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 426.0 in stage 0.0 (TID 226, xxx.xxx.hadoop.server, executor 52): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 359.0 in stage 0.0 (TID 248, xxx.xxx.hadoop.server, executor 100): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 488.0 in stage 0.0 (TID 123, xxx.xxx.hadoop.server, executor 63): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 354.0 in stage 0.0 (TID 205, xxx.xxx.hadoop.server, executor 43): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 506.0 in stage 0.0 (TID 221, xxx.xxx.hadoop.server, executor 43): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 461.0 in stage 0.0 (TID 292, xxx.xxx.hadoop.server, executor 32): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 423.0 in stage 0.0 (TID 253, xxx.xxx.hadoop.server, executor 32): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 367.0 in stage 0.0 (TID 234, xxx.xxx.hadoop.server, executor 89): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 410.0 in stage 0.0 (TID 140, xxx.xxx.hadoop.server, executor 78): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 511.0 in stage 0.0 (TID 164, xxx.xxx.hadoop.server, executor 62): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 484.0 in stage 0.0 (TID 28, xxx.xxx.hadoop.server, executor 12): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 328.0 in stage 0.0 (TID 230, xxx.xxx.hadoop.server, executor 19): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 348.0 in stage 0.0 (TID 258, xxx.xxx.hadoop.server, executor 36): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 333.0 in stage 0.0 (TID 255, xxx.xxx.hadoop.server, executor 27): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 485.0 in stage 0.0 (TID 256, xxx.xxx.hadoop.server, executor 27): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 331.0 in stage 0.0 (TID 271, xxx.xxx.hadoop.server, executor 19): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 411.0 in stage 0.0 (TID 282, xxx.xxx.hadoop.server, executor 36): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 482.0 in stage 0.0 (TID 290, xxx.xxx.hadoop.server, executor 41): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 471.0 in stage 0.0 (TID 288, xxx.xxx.hadoop.server, executor 41): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 490.0 in stage 0.0 (TID 291, xxx.xxx.hadoop.server, executor 93): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 379.0 in stage 0.0 (TID 285, xxx.xxx.hadoop.server, executor 93): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 350.0 in stage 0.0 (TID 216, xxx.xxx.hadoop.server, executor 77): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 396.0 in stage 0.0 (TID 287, xxx.xxx.hadoop.server, executor 60): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 321.0 in stage 0.0 (TID 210, xxx.xxx.hadoop.server, executor 90): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 337.0 in stage 0.0 (TID 235, xxx.xxx.hadoop.server, executor 60): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 90.0 in stage 0.0 (TID 264, xxx.xxx.hadoop.server, executor 86): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 332.0 in stage 0.0 (TID 243, xxx.xxx.hadoop.server, executor 92): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 446.0 in stage 0.0 (TID 284, xxx.xxx.hadoop.server, executor 92): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 496.0 in stage 0.0 (TID 156, xxx.xxx.hadoop.server, executor 81): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 385.0 in stage 0.0 (TID 241, xxx.xxx.hadoop.server, executor 22): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 514.0 in stage 0.0 (TID 266, xxx.xxx.hadoop.server, executor 25): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 462.0 in stage 0.0 (TID 222, xxx.xxx.hadoop.server, executor 90): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 401.0 in stage 0.0 (TID 263, xxx.xxx.hadoop.server, executor 22): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 450.0 in stage 0.0 (TID 228, xxx.xxx.hadoop.server, executor 25): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 225.0 in stage 0.0 (TID 276, xxx.xxx.hadoop.server, executor 4): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 403.0 in stage 0.0 (TID 239, xxx.xxx.hadoop.server, executor 7): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 430.0 in stage 0.0 (TID 280, xxx.xxx.hadoop.server, executor 4): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 505.0 in stage 0.0 (TID 215, xxx.xxx.hadoop.server, executor 91): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 201.0 in stage 0.0 (TID 269, xxx.xxx.hadoop.server, executor 99): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 138.0 in stage 0.0 (TID 257, xxx.xxx.hadoop.server, executor 99): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 314.0 in stage 0.0 (TID 260, xxx.xxx.hadoop.server, executor 47): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 501.0 in stage 0.0 (TID 10, xxx.xxx.hadoop.server, executor 2): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 397.0 in stage 0.0 (TID 272, xxx.xxx.hadoop.server, executor 86): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 453.0 in stage 0.0 (TID 217, xxx.xxx.hadoop.server, executor 45): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 497.0 in stage 0.0 (TID 270, xxx.xxx.hadoop.server, executor 17): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 330.0 in stage 0.0 (TID 268, xxx.xxx.hadoop.server, executor 47): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST ERROR org.apache.spark.scheduler.TaskSetManager: Total size of serialized results of 220 tasks (1036.7 MB) is bigger than spark.driver.maxResultSize (1024.0 MB)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 368.0 in stage 0.0 (TID 236, xxx.xxx.hadoop.server, executor 9): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 503.0 in stage 0.0 (TID 262, xxx.xxx.hadoop.server, executor 24): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 378.0 in stage 0.0 (TID 289, xxx.xxx.hadoop.server, executor 9): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 475.0 in stage 0.0 (TID 95, xxx.xxx.hadoop.server, executor 83): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 500.0 in stage 0.0 (TID 293, xxx.xxx.hadoop.server, executor 77): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 481.0 in stage 0.0 (TID 249, xxx.xxx.hadoop.server, executor 64): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST WARN org.apache.spark.scheduler.TaskSetManager: Lost task 499.0 in stage 0.0 (TID 273, xxx.xxx.hadoop.server, executor 83): TaskKilled (Stage cancelled)
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST ERROR com.xxxxx.xxxxxx.xxx.xxx.Boot$: boot error
29-03-2024 09:53:10 INFO - org.apache.spark.SparkException: Job aborted.
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:224)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:154)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:104)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:102)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.command.DataWritingCommandExec.doExecute(commands.scala:122)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:80)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:80)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:656)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.DataFrameWriter$$anonfun$runCommand$1.apply(DataFrameWriter.scala:656)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:77)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:656)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:273)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:267)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:225)
29-03-2024 09:53:10 INFO - at com.xxxxx.xxxxxx.xxx.xxx.writer.WriterImpl.writeDataToHDFS(WriterImpl.scala:27)
29-03-2024 09:53:10 INFO - at com.xxxxx.xxxxxx.xxx.xxx.executor.ExportExecutor.execute(ExportExecutor.scala:45)
29-03-2024 09:53:10 INFO - at com.xxxxx.xxxxxx.xxx.xxx.executor.base.CommandExecutorImpl$class.execute(CommandExecutor.scala:36)
29-03-2024 09:53:10 INFO - at com.xxxxx.xxxxxx.xxx.xxx.Boot$$anon$1.execute(Boot.scala:49)
29-03-2024 09:53:10 INFO - at com.xxxxx.xxxxxx.xxx.xxx.Boot$.runJob(Boot.scala:55)
29-03-2024 09:53:10 INFO - at com.xxxxx.xxxxxx.xxx.xxx.Boot$.main(Boot.scala:30)
29-03-2024 09:53:10 INFO - at com.xxxxx.xxxxxx.xxx.xxx.Boot.main(Boot.scala)
29-03-2024 09:53:10 INFO - at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
29-03-2024 09:53:10 INFO - at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
29-03-2024 09:53:10 INFO - at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
29-03-2024 09:53:10 INFO - at java.lang.reflect.Method.invoke(Method.java:498)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.SparkSubmit$.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:904)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.SparkSubmit$.doRunMain$1(SparkSubmit.scala:198)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.SparkSubmit$.submit(SparkSubmit.scala:228)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:137)
29-03-2024 09:53:10 INFO - at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
29-03-2024 09:53:10 INFO - Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Total size of serialized results of 219 tasks (1029.1 MB) is bigger than spark.driver.maxResultSize (1024.0 MB)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1651)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1639)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1638)
29-03-2024 09:53:10 INFO - at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
29-03-2024 09:53:10 INFO - at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1638)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:831)
29-03-2024 09:53:10 INFO - at scala.Option.foreach(Option.scala:257)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:831)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:1872)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1821)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1810)
29-03-2024 09:53:10 INFO - at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
29-03-2024 09:53:10 INFO - at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:642)
29-03-2024 09:53:10 INFO - at org.apache.spark.SparkContext.runJob(SparkContext.scala:2039)
29-03-2024 09:53:10 INFO - at org.apache.spark.SparkContext.runJob(SparkContext.scala:2060)
29-03-2024 09:53:10 INFO - at org.apache.spark.SparkContext.runJob(SparkContext.scala:2079)
29-03-2024 09:53:10 INFO - at org.apache.spark.SparkContext.runJob(SparkContext.scala:2104)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:945)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDD.withScope(RDD.scala:363)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDD.collect(RDD.scala:944)
29-03-2024 09:53:10 INFO - at org.apache.spark.RangePartitioner$.sketch(Partitioner.scala:309)
29-03-2024 09:53:10 INFO - at org.apache.spark.RangePartitioner.<init>(Partitioner.scala:171)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec$.prepareShuffleDependency(ShuffleExchangeExec.scala:224)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.prepareShuffleDependency(ShuffleExchangeExec.scala:91)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec$$anonfun$doExecute$1.apply(ShuffleExchangeExec.scala:128)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec$$anonfun$doExecute$1.apply(ShuffleExchangeExec.scala:119)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.catalyst.errors.package$.attachTree(package.scala:52)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.exchange.ShuffleExchangeExec.doExecute(ShuffleExchangeExec.scala:119)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.InputAdapter.inputRDDs(WholeStageCodegenExec.scala:371)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SortExec.inputRDDs(SortExec.scala:121)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.WholeStageCodegenExec.doExecute(WholeStageCodegenExec.scala:605)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:131)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$execute$1.apply(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan$$anonfun$executeQuery$1.apply(SparkPlan.scala:155)
29-03-2024 09:53:10 INFO - at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:152)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:127)
29-03-2024 09:53:10 INFO - at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:180)
29-03-2024 09:53:10 INFO - ... 36 more
29-03-2024 09:53:10 INFO - 2024-03-29 09:53:10 JST INFO com.xxxxx.xxxxxx.xxx.xxx.Boot$: going to stop the spark
29-03-2024 09:53:17 INFO - 2024-03-29 09:53:17 JST INFO com.xxxxx.xxxxxx.xxx.xxx.Boot$: going to exit from main existStatus:1
29-03-2024 09:53:18 INFO - Process with id 53171 completed unsuccessfully in 105 seconds.
29-03-2024 09:53:18 ERROR - Job run failed!
|